
Edit - I had to rebuild this post and some of the original details on the target website originally used in the web scraping have been changed by the site maintainer. Rather than redo all the work, this content is rebuilt using print statements where the dynamic output has failed. The original approach and thinking that I had hoped to convey to the reader remains.
Introduction
This is the first post in a series that explores web scraping using R to collect the Commonwealth War Graves Commission (CWGC) data. I had been looking for a project to practice some web scraping techniques and rather than follow some generic tutorial, I thought it made sense to collect some data I had a genuine interest in. The website offers a download option which outputs the results in a spreadsheet - limited to a maximum of 80,000 rows - but I wanted to see how it might be done with web scraping methods.
With the darkness, ‘the melancholy work of the burial of the dead was begun. The special party told off for this work dug graves in High Wood itself, and all the dead who could be found were buried side by side there.’ ‘As one looked on the weary band of tired and muddy comrades who had come to fulfill this last duty to their friend, one felt in a way one seldom does at an ordinary funeral, that … [the dead] really were to be envied, since for them the long-drawn agony of war was at an end.’
Hanson, N. (2019), Unknown Soldiers: The Story of the Missing of the Great War, Lume Books
The CWGC database lists 1,741,972 records, which represents the total number of war dead that the CWGC commemorates. This number is slowly increasing as researchers uncover individuals whose role in the wars had previously been unknown. In addition to searching for an individual by name, the website offers a number of advanced search terms that may be used to refine the search. These terms include:
- War (WWI or WWII)
- Country served with (predominantly Commonwealth countries)
- Cemetery or memorial
- Country of commemoration (over 150 countries)
- Branch of service (Army, Air Force, Navy…)
- Date of death
- Age at death
- Unit (Regiment, Squadron, Ship…)
- Rank (Private, Corporal…)
- Honours & Awards (DFC, MM, VC, DSO…)
My initial idea was to use the site search terms as the basis for the script. These could be used to divide the data into smaller sets for scraping. By default, the results are paginated up to 500 pages, each with 20 records, for a maximum of 10,000 records. This meant that I needed a set of search terms that would generate sets of results that did not individually exceed 10,000 records. With this in mind, trying to split the results by War, Country Served With, Country of Commemoration and Branch of Service was not going to work. The Age at Death term was not that helpful either, since there were more than 500,000 18 year-olds killed in each war. Furthermore, a quick scan through the results from some random searches showed a lot of this data field was missing. I briefly considered searching by Cemetery and Memorial but a quick check showed the Thiepval memorial has over 70,000 names on it.
The first day of the battle of the Somme killed almost 20,000 soldiers, so splitting by Date of Death could also be ruled out. I explored this a bit further and a search for WWI, Army, Served with UK, Commemorated on Thiepval Memorial, Killed on 01/07/1916 showed 12,408 names - a truly horrific number. This was certainly an exceptional case but it was clear that the script would have to use multiple search terms to get below the threshold of 10,000 records.
This raised an ethical question about web scraping - how many requests are reasonable before the scraping activity potentially affects the performance of the website? Scraping also runs the risk of being identified as a DoS attack, which could lead to your access to the website being blocked at best, or a criminal prosecution at worst. After much fiddling about and some initial coding, I decided against proceeding with a fully-automated script. Using the site download option was not my preferred approach, but it still left a lot of scope to demonstrate some useful scraping methods. Equally, even in a learning environment, its always questionable to spend a lot of time coding a complex solution when a simpler approach will suffice.
Installing R Packages
This project uses the rvest package for the web scraping functions, and some other standard packages for data manipulation and visualization. R packages can be installed using:
|
|
Once installed, packages can then be loaded with:
|
|
If you tend to write code on multiple machines as I do, it can become a bit confusing to remember which packages are installed on which machine. Whilst this is easy to fix, a simple way around this is to use the following code snippet at the start of your work. Just add in the required packages, and it will install and load them as required.
|
|
 Figure 1. Commonwealth cemetery in Krakow, Poland. August 16, 2014.
Figure 1. Commonwealth cemetery in Krakow, Poland. August 16, 2014.
List of Countries With Memorials
As part of the initial exploration, I wanted to get a breakdown of the number of war dead commemorated in each country. To do this, I looped through each country and retrieved the number of records for each. The list of countries with graves and memorials was extracted from a drop-down element on the webpage.
First, I defined the main URLs to be scraped:
|
|
The contents of the memorial webpage was retrieved using the read_html() function, which returns an XML document.
|
|
When trying new functions, I always check the class of the objects returned. In my experience, unexpected results are often caused by incorrectly applying functions to the wrong object class.
|
|
|
|
Normally the Environment panel in Rstudio is quite useful for inspecting data objects in the work-space. However, in the case of an XML object, it’s not that helpful and the standard View() command is a bit hit-and-miss. On my laptop I found that the View() command did not work for an XML object, but it did work on my main PC (this may have to do with some differences in package versions). An alternative is to use the xml_structure() function, but the output can be cumbersome to read in the console.
|
|
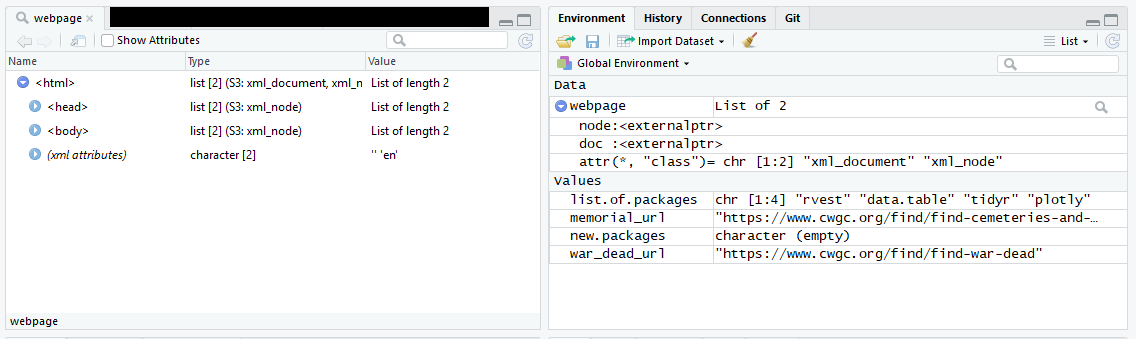 Figure 2. View contents of XML object in Rstudio
Figure 2. View contents of XML object in Rstudio
The list of countries where graves or memorials are found can be retrieved from the Country drop-down box on the search form. To reference this element, one can use either the HTML Id value or the XPath. In Chrome, you can right-click the element and choose ‘Inspect’ or use ‘Ctrl-Shift-I’. This opens up Chrome Dev Tools, where you can see the HTML elements and associated tags. The drop-down element has id = “country”, or alternatively you can copy the XPath by right-clicking the element and choosing ‘Copy XPath’.
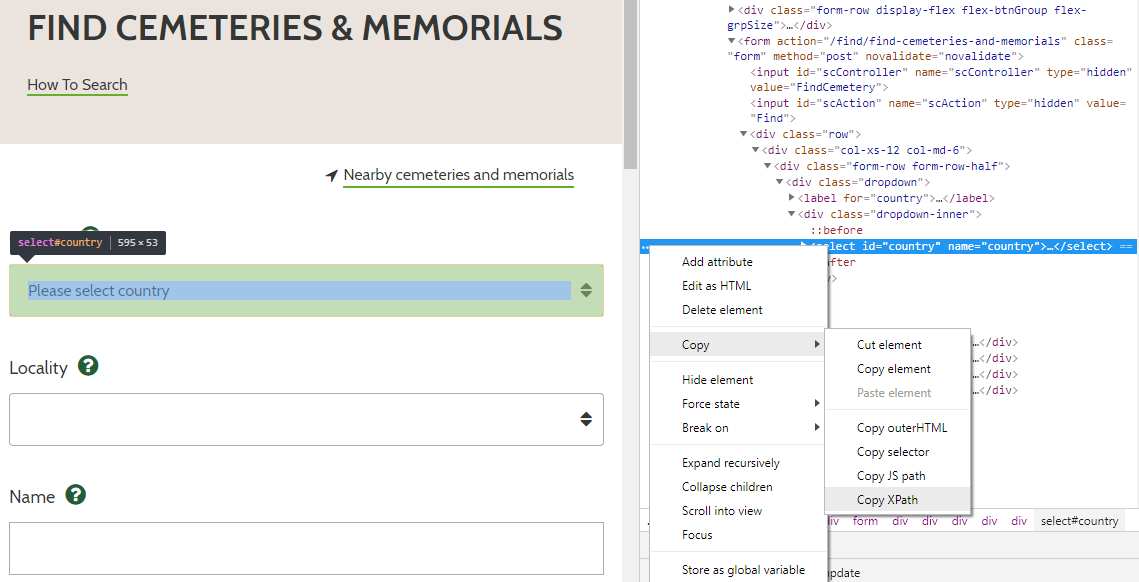 Figure 3. HTML element Id and XPath from https://www.cwgc.org
Figure 3. HTML element Id and XPath from https://www.cwgc.org
The contents of the element can be retrieved by using the html_node() function in conjunction with the relevant CSS selector or the XPath. If using the XPath copied from Chrome Dev Tools, change the double quotes around “country” to single quotes i.e. ‘country’.
|
|
Using class() shows that the output is an XML node object.
|
|
|
|
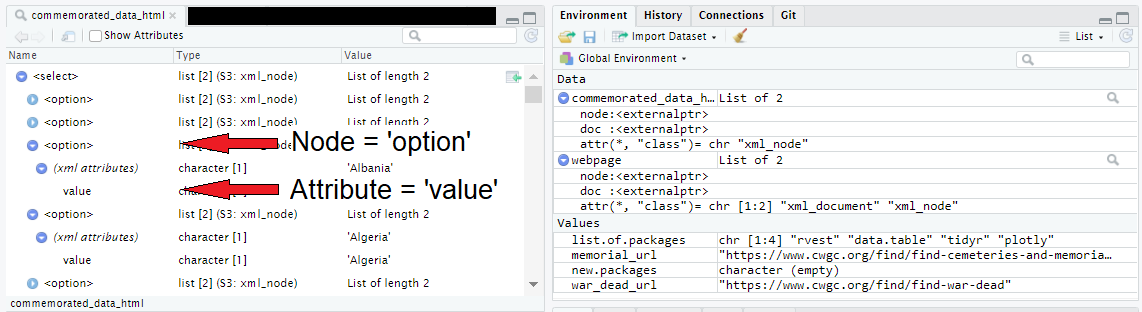 Figure 4. RStudio view of HTML node structure
Figure 4. RStudio view of HTML node structure
The nodes are labelled ‘option’, and each has an xml attribute labelled ‘value’. The xml attributes contain the list of countries that we are trying to extract. These are retrieved using the html_attr() method.
|
|
Then we tidy up the list by removing the first two elements ("" and “all”):
|
|
And finally, the list of countries is:
|
|
|
|
Finally, save the results for later use:
|
|
Conclusion
This post has discussed the initial exploration of the data source and has introduced the tools and packages that will be used. It also showed how to retrieve a list of all the countries that have memorials and graves administered by the CWGC.
Using the list of countries, the next post will show how to automatically extract the number of graves in each country.