
Edit - I had to rebuild this post and some of the original details on the target website originally used in the web scraping have been changed by the site maintainer. Rather than redo all the work, this content is rebuilt using print statements where the dynamic output has failed. The original approach and thinking that I had hoped to convey to the reader remains.
Introduction
This is the second post in a series that explores data collection using R to collect the Commonwealth War Graves Commission (CWGC) dataset.
Once I had extracted the list of the countries from the website, I proceeded to get the number of graves and memorials for each country, with a break-down for both WWI and WWII. I initialized a dataframe to store the results, and two loops to step through each war and each country.
|
|
|
|
The number of records for each country was obtained from the main URL and a HTML session was set up for the duration of the scraping. The html_form() function was used to extract the form structure from the page.
|
|
The output was a list of lists, and the third list element contained the search fields for the form (LastName, Initials, FirstName and so on). Specifically, I used the ‘CountryCommemoratedAt’ and ‘War’ fields for the automated search.
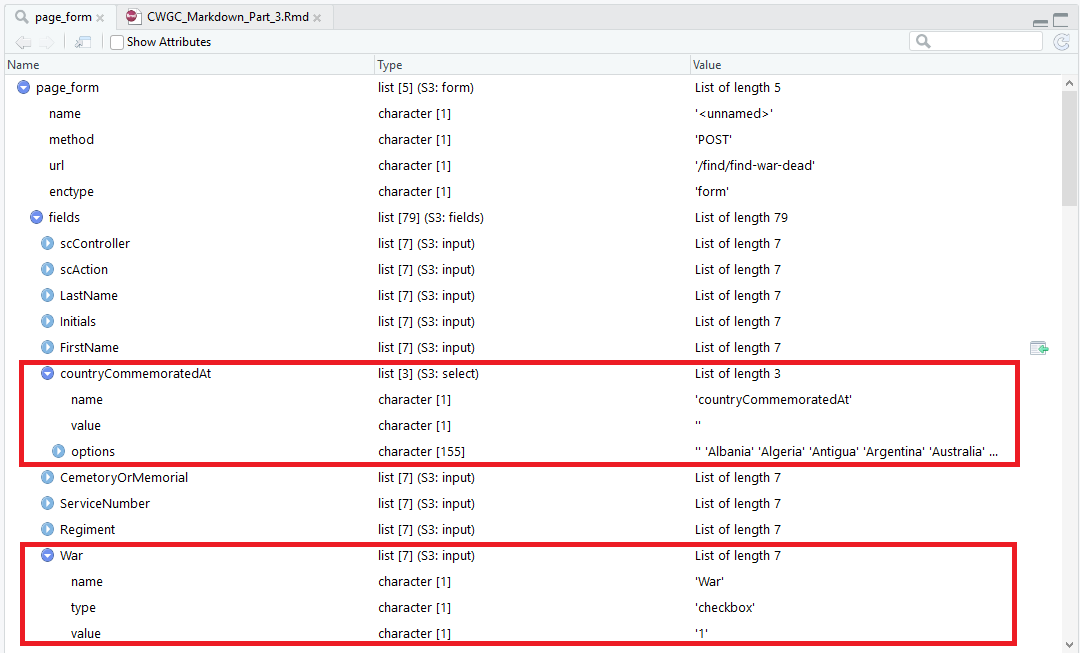
Submitting a Form
After selecting the third element, I used the set_values() method to set the values in the form, where the variables war and commemorated are set by the loops roughly defined previously. Lastly, the form is submitted and the results are retrieved.
|
|
The parsed HTML response contained a count of the number of records, which was ultimately what I was trying to determine, but first I needed to figure out which element had the relevant data. I did a manual search on the website by selecting a country and war (for instance, selecting ‘France’ and ‘WWI’). From the result, I could copy the XPath for the element containing the number of records.
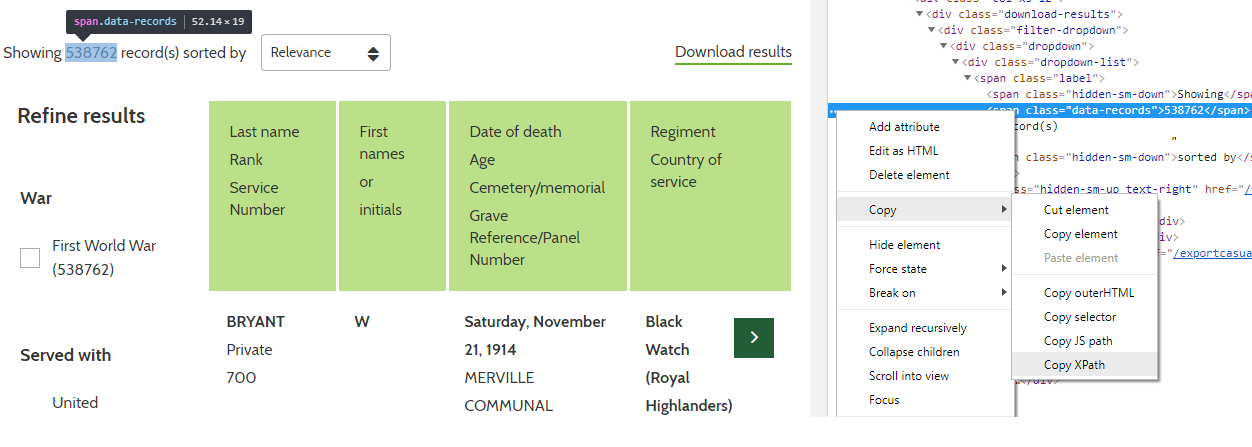
Once I had the XPath, I was able to retrieve the relevant HTML elements and attribute values using the functions as previously described in the first post:
|
|
At this point, I had the number of graves commemorated for the respective country and war and all that remained was to copy the results to the dataframe initialized earlier, and row bind to any previous results from other iterations.
|
|
Its probably not necessary in this case, considering the low volume of page requests, but if you were concerned about overloading the website then we can introduce a delay between each loop iteration using the Sys.sleep() command:
|
|
Putting it all Together
|
|
Number of Graves by Country
I then calculated the total number of graves commemorated per country for both wars. First I converted the dataframe from long format to wide format - if you’re not sure what this means, check out tidyr for a helpful explanation. This split out the results for each war and placed them in their own columns. A total column is derived by simply summing the two values.
|
|
At this point, I checked that the results tallied with the total number of graves commemorated by the CWGC (1,741,938), but I was short 68,887 records. Comparing the results against the website showed I had omitted the category for civilians (‘Civilian War Dead’) which was not included in the list of countries that was used for the loop. I added this in manually and re-scraped the data.
|
|
Once this was done, I verified that my results matched the CWGC totals and saved the results to a *.rda file for later use.
|
|
The final output gives a table of the number of graves in each country and each for each war:
|
|
Table: Table 1: Graves per Country and War
| commemorated | war-1 | war-2 | sum |
|---|---|---|---|
| Albania | 0 | 48 | 48 |
| Algeria | 19 | 2051 | 2070 |
| Antigua | 0 | 2 | 2 |
| Argentina | 2 | 13 | 15 |
| Australia | 3498 | 9969 | 13467 |
| Austria | 7 | 577 | 584 |
| Azerbaijan | 47 | 0 | 47 |
| Azores | 0 | 52 | 52 |
| Bahamas | 2 | 58 | 60 |
| Bahrain | 0 | 0 | 0 |
Conclusion
This post demonstrated how to use simple web-scraping techniques to get a breakdown of the number of graves commemorated by the CWGC in each country. The following post will show how this information is used to download the data for further analysis.