
Introduction
The post provides a brief introduction to Large Language Model (LLM) document augmentation. It discusses why this is necessary and provides a simple example of how it might be achieved. The code uses LangChain as the main framework, ChromaDB for the vector storage, and OpenAI language models for embeddings and chat.
The Problem
One of the primary limitations of LLMs is their knowledge cutoff date. Since LLMs are trained on static datasets, they naturally lack information about any current events or recent developments which have occurred after the dataset was defined. They are essentially frozen in time and therefore unable to provide up-to-date information on any subjects or developments that have occurred subsequent to their training. For example, imagine that in the last week, a previously unknown moon orbiting Neptune had been discovered by astronomers. Commercially available LLMs can be trained over the course of months, so the latest models would most likely incorrectly answer questions relating to Neptune’s moons.
LLMs are also lacking with tasks that requiring specialized or niche knowledge, since they are mostly trained on data representing general knowledge, and lack depth in specific domains or sectors. In these situations, responses can be inaccurate, superficial or generalized in nature. Say for instance that you wish to use a LLM in an internal company-wide application. An off-the-shelf LLM will lack training on the company’s specific information which is likely to be proprietary, specialized, not publicly available and unpublished. This lack of domain knowledge and specialization can lead to hallucinations, where plausible but factually inaccurate responses are generated in the absence of detailed training data.
Retrieval Augmented Generation
To address these limitations, one non-trivial option would be to re-train the model, however this is an unattractive proposition given the potential time and resources that would be needed. Retrieval Augmented Generation (RAG) provides a far simpler method for supplementing an LLM’s training data with specialized and up-to-date information, to enhance responses and deliver contextually relevant responses.
Implementing RAG typically follows a structured process. Supplemental sources (user files, proprietary company data, product data, research papers and so on) are loaded and pre-processed into raw text, which is then split into smaller chunks called documents. Note that in the context of NLP, the word ‘document’ does not have the traditional meaning, but rather refers to a unit of data that can range from a single sentence to an entire book. These chunks of text are then transformed into vector representations - word embeddings - which capture the semantics or meaning of the text. During the embedding process a word, sentence or whole text file is converted into a sequence of numbers (a vector), such that similar texts will have similar vector representations. Using semantic similarity searches, the embeddings provide an efficient means of finding texts that are most relevant and similar in context.
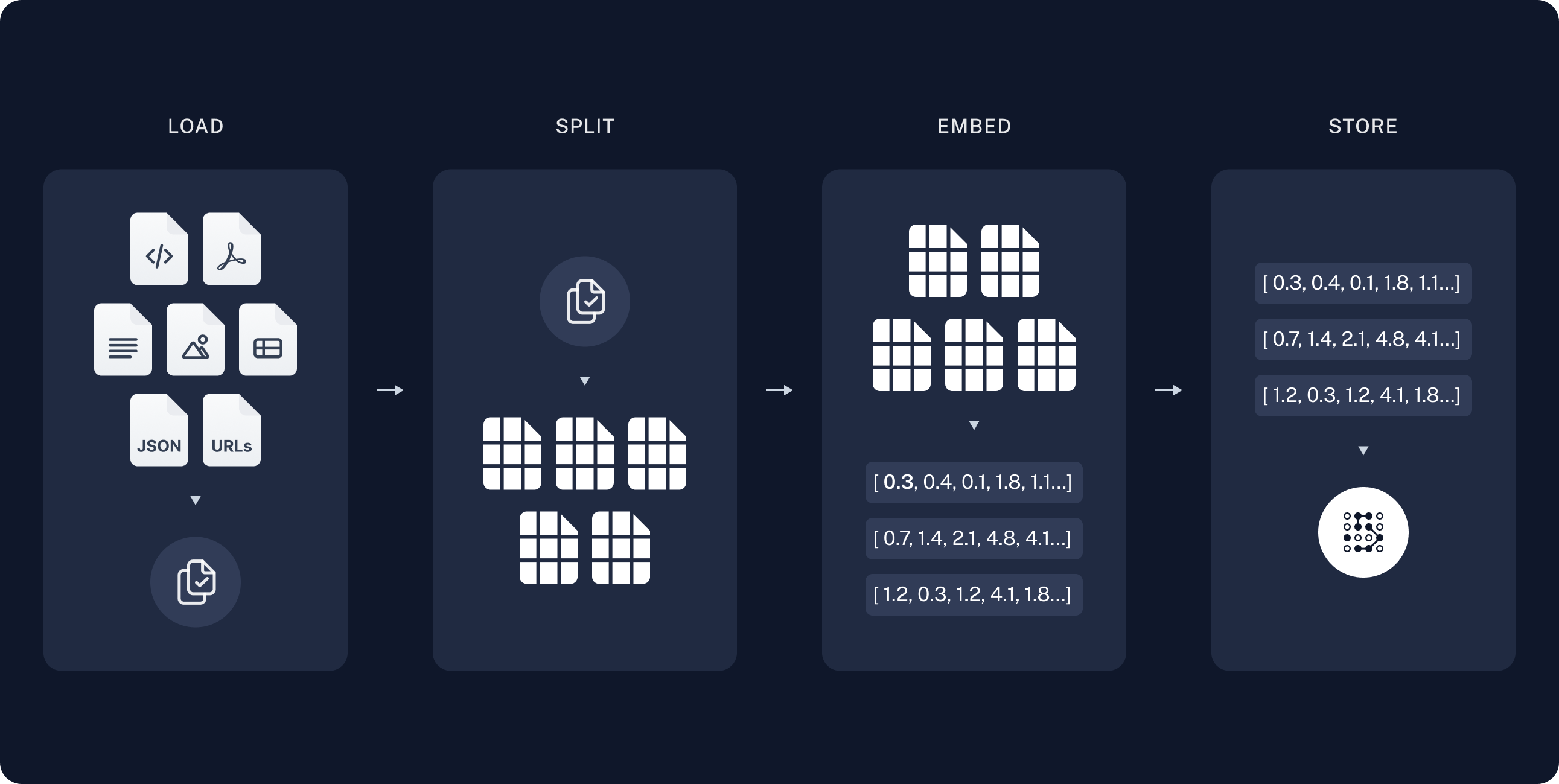
With RAG, when a user query is submitted to a chat model, the system searches through the stored embeddings to find the most pertinent document chunks based on their semantic similarity to the query. These chunks are retrieved and then incorporated into the original user query. This augmented query is sent to the LLM, providing additional context and information to improve the generated response. This process has been aptly described as similar to giving a student a cheat sheet right before an exam. In this fashion, the LLM generates output derived from its underlying language understanding, and augmented with the bespoke information provided by the RAG system.
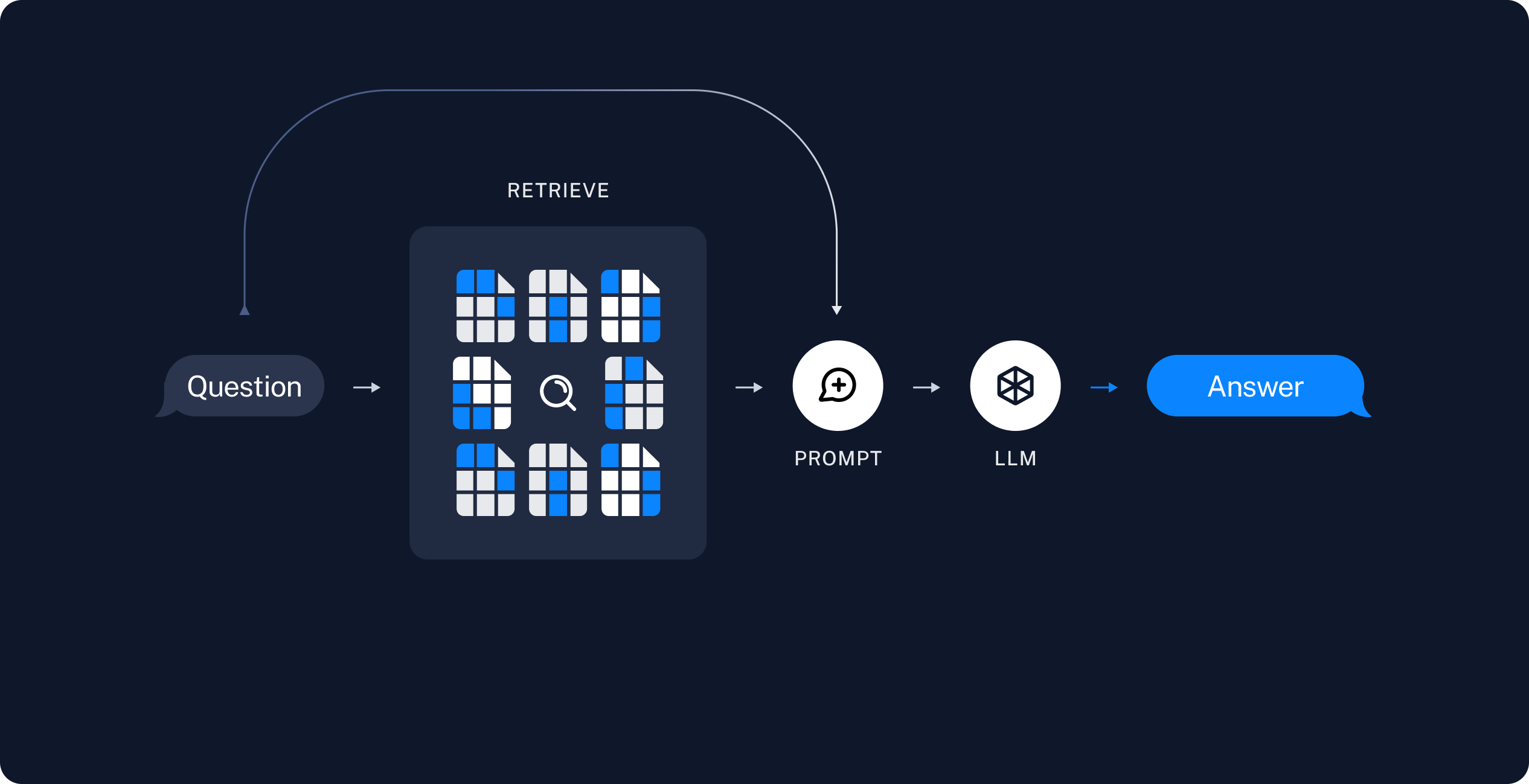
The RAG Implementation process:
- Collect supplemental data sources
- Ingest and process data into chunks
- Convert the text to word vector representation
- Store the resulting word vectors
- Input a user query to be sent to the chat model
- Convert the query to word vector representation
- Retrieve the stored vectors that are semantically closest to the user query
- Modify the prompt by incorporating the retrieved vectors
- Submit the query to the LLM
Libraries
This post uses LangChain as the main framework. I won’t go into any great detail regarding LangChain, except to say that it is an open-source framework for the development of applications powered by LLMs. Among its many capabilities, it provides a robust framework for implementing RAG pipelines and offers utilities for document loading, text splitting, and integration with various embedding models and vector stores. A main feature of LangChain is its use of ‘chains’ that seamlessly combine document retrieval, prompt engineering, and language model interaction.
Document embeddings are typically stored in a vector database, which are specialized database systems designed to store, index, and efficiently search high-dimensional vector data. These databases are optimized for handling vector embeddings. The code in this post uses Chroma DB, which is an open-source vector database specifically designed for AI applications. It easily integrates with LangChain, making it an attractive option for experimentation. The vector database can be kept in-memory, in the local file system or in a server-based location.
This project reminded me why I prefer R over Python sometimes. LangChain 0.3 was released in September 2024, and a lot of the online materials and tutorials use older versions, so deprecation warnings and package conflicts abound. You can get into a real mess trying to figure out the embeddings too, with options to use Chroma for LangChain, or LangChain for Chroma. I used the most recent versions where possible, since I’m not a fan of learning deprecated functions. For reference, here are some of the package versions used in the subsequent code.
|
|
|
|
APIs
This post uses OpenAI models, so you’ll need a paid account to use their API if you want to run the code. There used to be a free tier, but its changed relatively recently and I had to add a small amount of credit to my account. There are plenty of resources online showing you how to sign up. Once you have an API key, you will have to import it into your development environment. If you are using a conda environment, you can add it to the environment variables and then import it.
|
|
First we connect to the LLM - the chat model - from OpenAI. This can be changed to whatever model you wish naturally, so long as you have the required access or downloads in the case of local model usage.
|
|
Document Loading
Next we set up a document splitter, which splits the input data into chunks prior to making the embeddings. The chunk_size parameter determines the number of characters in each split and the chunk_overlap is used to reduce the risk of information loss at the chunk boundaries.
The manner in which chunking is implemented can significantly impact model behavior and overall performance. Generally speaking, smaller chunks increase precision and permit specific information retrieval, whereas larger chunks can be beneficial for conversational applications where a broader context is required. On the other hand, chunks that are too small may not contain sufficient information about a subject and overly large chunks may have a context that is too broad, thus reducing its relevance and similarity score. There is also a resource and computational trade-off that must be considered. Smaller chunk sizes result in more chunks, which increases search time and storage requirements and larger chunks will reduce search times and storage needs.
|
|
For the purposes of this example, I am using an excerpt from an autobiography that I recently read. To the Limit: An Air Cav Huey Pilot in Vietnam is the personal account of a helicopter pilot in the Vietnam War. It is a great book written by Tom Johnson, and I highly recommend it. It is improbable (but not impossible) that an LLM would have been trained on the information in this book, so we can use this niche document to demonstrate RAG. The following is a random 2000 character sample from the book:
“war, many individual Rotary Wing Classes suffered even heavier losses than that of the average helicopter crew. I graduated 16th of 286 men in Warrant Officer Rotary Wing Aviation Class 67-5. In the twelve months after we received our Army aviator wings at Fort Rucker, Alabama, 1 out of every 13 of us died in South Vietnam. Of those who died, the average time in country was 165 days and the average age was 23.11 years.’ 1, Statistical data provided by Vietnam Helicopter Pilots Association. Made possible only through the individual efforts of Gary Roush and the other members of the Data Base Committee as listed in the 2004 Membership Directory. The An Lao Valley Incident Tonight, this 19-year-old will most likely leave us. His wounds are massive. Like others before him, he thrashes about on the hard alumi- num floor bathed in blood and suffering. Repeatedly, he calls for his mother, not his God. At great risk to ourselves, we will push our flying abilities and this helicopter to the brink of disaster trying to save him. Although cloaked in darkness, we must fly hard and low, cutting every corner. In spite of all my efforts, he will likely make the transition from life to death. His soul will depart, and his earthly body will finally lie in peace, without pain. September 5, 1967 At 0430 hours the company night clerk awakens me and advises me that Major Eugene Beyer,! A Company’s commanding officer, has picked me to “volunteer” for an emergency night resupply mission. Not fully awake, I plant my feet over the side of my cot and push the mosquito netting aside while attempting to comprehend the rapid briefing being given by the clerk. I “roger” as though I actually under- stand all he has said, then reach across the wooden pallets covering the dirt floor between my bunk and that of Warrant Officer James Arthur Johansen. Shaking him awake, I ask him to go with me. Though more asleep than awake, he agrees. 1. Eugene Beyer was later promoted to a colonel. He is now retired” - Tom A. Johnson
Document Chunking
Now we load the custom document and split it into chunks according to the previously defined splitting function. The output is a Document object containing a list of document chunks. Each chunk contains metadata and the actual text.
|
|
|
|
The page_content component is extracted and stored in a simple list that will be fed into the embedding model.
|
|
Embedding
Next, define the embedding function. The function uses an OpenAI model for making embeddings…
|
|
…and then call the function to make the embeddings. The output is an array of numbers. OpenAI embeddings produce a vector with 1536 dimensions i.e. each piece of text is represented by a vector of 1536 numbers.
|
|
Vector Storage
There are two alternatives for using Chroma: use the LangChain Chroma functions, or use a Chroma client. I used the latter, since it gives finer control over how the data is stored, particularly regarding collections. This may of course be quite feasible using the LangChain implementation but I could not get the desired output.
|
|
|
|
Documents can be added to collections, which are logical groupings of documents that can be constructed according to user preference. A collection could potentially be created per user, per document author, per document topic and so on. See Chroma DB documentation for more details on collections.
|
|
|
|
The document chunks are added to the collection object and stored in the vector database, along with a unique identifier per chunk, the OpenAI embeddings and user-defined metadata. The metadata is a dictionary of key-value pairs.
|
|
|
|
Running the add() function multiple times will add multiple copies of the documents to the vector database, so make sure to keep this in mind if playing around with the chunking options. If this presents as a problem, the simplest approach may be to delete the collection and start again.
|
|
The count() function is used to check the number of records.
|
|
|
|
The contents of the collection can be inspected using peek(), which will show the first 10 items, or peek(n) which will show a particular entry. The output shows the id, embedding vector, the document text and the metadata.
|
|
|
|
Collections can be listed simply with reference to the client.
|
|
|
|
Vector Retrieval
I extracted a niche fact from the supplementary document and checked if ChatGPT was able to answer a query relating to it. It is certainly possible that this information is included in the model’s training data, so its worth checking how the student performs on the exam without a cheat sheet.
|
|
|
|
This is a good example of a hallucination - the response seems plausible and to the casual user it would be natural to assume it is correct. I tried the same query with other ChatGPT models and Perplexity, and the responses varied. If we run the model again, the numbers change again so it is safe to say that this information is not included in the training data.
|
|
|
|
Now we see if a similarity search with our bespoke vector store can do any better. This does not deliver a fully formed answer (since the output is only a copy of the stored text) but it will hopefully be indicative of whether the augmented information is useful. By default, the following function returns the 4 closest matches, but this can be customized using k.
|
|
|
|
A related function can be used to also output the similarity score in addition to the vector text.
|
|
|
|
Prompt Augmentation
By now, we have discussed how to load a document, chunk it, make embeddings, add them to a vector database and retrieve vectors. The last piece of the puzzle is to augment the user query with the retrieved vectors and submit this to a chat model. The additional context provided should thus improve the quality of the model’s response.
There are two approaches here: the first uses retrievalQA which is deprecated (I know, I know…) but it is simpler to present. The second uses LangChain Expression Language (LCEL), which is used to chain together LangChain components, where the output from one element becomes the input to the next. This section also introduces retrievers, which are a broad class of objects that take unstructured inputs and retrieve documents.
Deprecated
|
|
|
|
LCEL
|
|
|
|
Both augmented queries and responses provide a simple but fantastic demonstration of the power of RAG in improving model utility. The language model was successfully provided with additional context (i.e. 1 in 13 men died) which was not included in its prior training data, and was able to correctly calculate and state that 22 men from the aviator class died in Vietnam.
Conclusion
Document augmentation with Retrieval Augmented Generation (RAG) offers a powerful solution to overcome the inherent limitations of LLMs. By supplementing the model’s knowledge with up-to-date and specialized information, RAG enables more accurate, contextually relevant, and timely responses. This approach not only addresses the knowledge cutoff issue but also enhances the model’s performance in niche domains without the need for extensive retraining. The future success and trajectory of language models lies in their adaptability and ease of knowledge integration and RAG is demonstrably a significant complementary tool to this end.
Further Reading and References
- LangChain Tutorial https://python.langchain.com/docs/tutorials/rag/
- Main image from DALL-E